
Los tiempos han cambiado
Uno de los efectos, tremendamente beneficiosos, que tenemos cuando adoptamos el cloud en el desarrollo de nuestras aplicaciones es que tenemos muchas más opciones a nuestro alcance. Y el caso de las bases de datos no es una excepción. Así, tenemos disponibles desde las clásicas bases de datos relacionales, totalmente gestionadas por el proveedor de nube, y también todo tipo de bases de datos NoSQL: de tipo clave-valor, documento, grafo, tabla, etc.
Sin embargo, como nos ocurre bastante a menudo, nos encontramos con una inercia. Una inercia provocada porque durante años o décadas nos hemos acostumbrado a diseñar el modelo de datos para un mundo relacional… no hay más que recordar las clases en la universidad sobre la tercera forma normal, o incluso, en mi caso, algo como «cálculo relacional» en la que se definían las tablas y sus relaciones como expresiones matemáticas…
Pues bien, cuando nos enfrentamos al diseño de un modelo de datos para una base de datos no SQL tenemos que «desaprender y volver a aprender» a hacer este diseño, olvidándonos de como lo hacíamos hasta ese momento con las relacionales, simplemente, no siguen las mismas reglas.
Las bases de de datos relacionales vienen de un tiempo en el que el almacenamiento era tremendamente caro y nos esforzábamos en que la información no estuviese repetida para ahorrar dinero. Los tiempos han cambiado, y ahora, hablando de aplicaciones que tienen que escalar, es más caro el tiempo de CPU que el espacio en disco, así que ahora (por anti-intuitivo que pueda resultarnos) la cosa trata de repetir información.

RDBMS vs NoSQL
En las bases de dato relacionales (RDBMS):
- Los datos se pueden consultar de manera flexible, pero las consultas son relativamente caras en tiempo de computación y no escalan bien
- Se diseña el modelo de datos para ser consultado de manera flexible pero no nos ocupamos de como se va a implementar la aplicación que accede a los mismos o a su rendimiento.
En las bases de datos NoSQL
- Los datos pueden ser accedidos de una manera muy eficiente en un número limitado de formas, y fuera de estas los accesos son caros y lentos
- Se diseña el modelo de datos específicamente para que las consultas y escrituras que hará la aplicación sean lo más rápidas y baratas posibles. La estructura de datos está pensada para las necesidades especificas de los casos de uso.
Por lo tanto, en el caso de NoSQL, no deberías empezar el diseño del modelo de datos hasta que sepas las consultas y escrituras que va a hacer la aplicación. De esta manera, el primer paso en el diseño de un modelo de datos NoSQL es identificar cómo son los patrones de acceso a los datos. Y el modelo se diseña para satisfacer estas consultas, es decir, al contrario de como ocurre en el mundo relacional de manera tradicional.
Otra best practice en NoSQL es tener los datos lo más juntos posible, y no tener varias colecciones diferentes para luego hacer joins en tiempo de ejecución. Esto es posible gracias a que este tipo de bases de datos no tienen un esquema rígido definido, por lo que en una misma colección de documentos se puede almacenar información heterogénea si es necesario.
Para ilustrar lo mejor es ver un ejemplo sencillo de modelado con MongoDB (una de las bases de datos noSQL más usadas):
El ejemplo es sobre un blog, en el que se quieren guardar en una base de datos los artículos, los comentarios sobre los mismos y las etiquetas asociadas.
En un mundo relacional tendríamos esto (tres tablas), con una relación 1-n entre ellas:
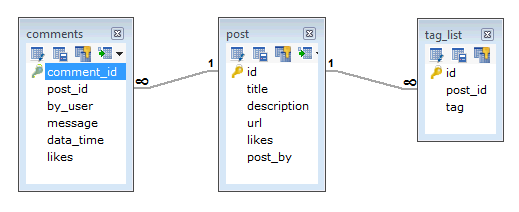
Sin embargo, en MongoDB tendríamos un sólo documento con toda la información en él. No haría falta por lo tanto hacer un Join entre las tres tablas para pintar una página donde aparece la información del artículo, los comentarios y las etiquetas.

Conclusión
No diseñes el modelo de datos de una NoSQL como si fuera una relacional. Es un medio totalmente distinto, donde las viejas reglas no sirven, hay que aplicar reglas nuevas.


Deja un comentario